
Graph Retrieval Augemented Generation
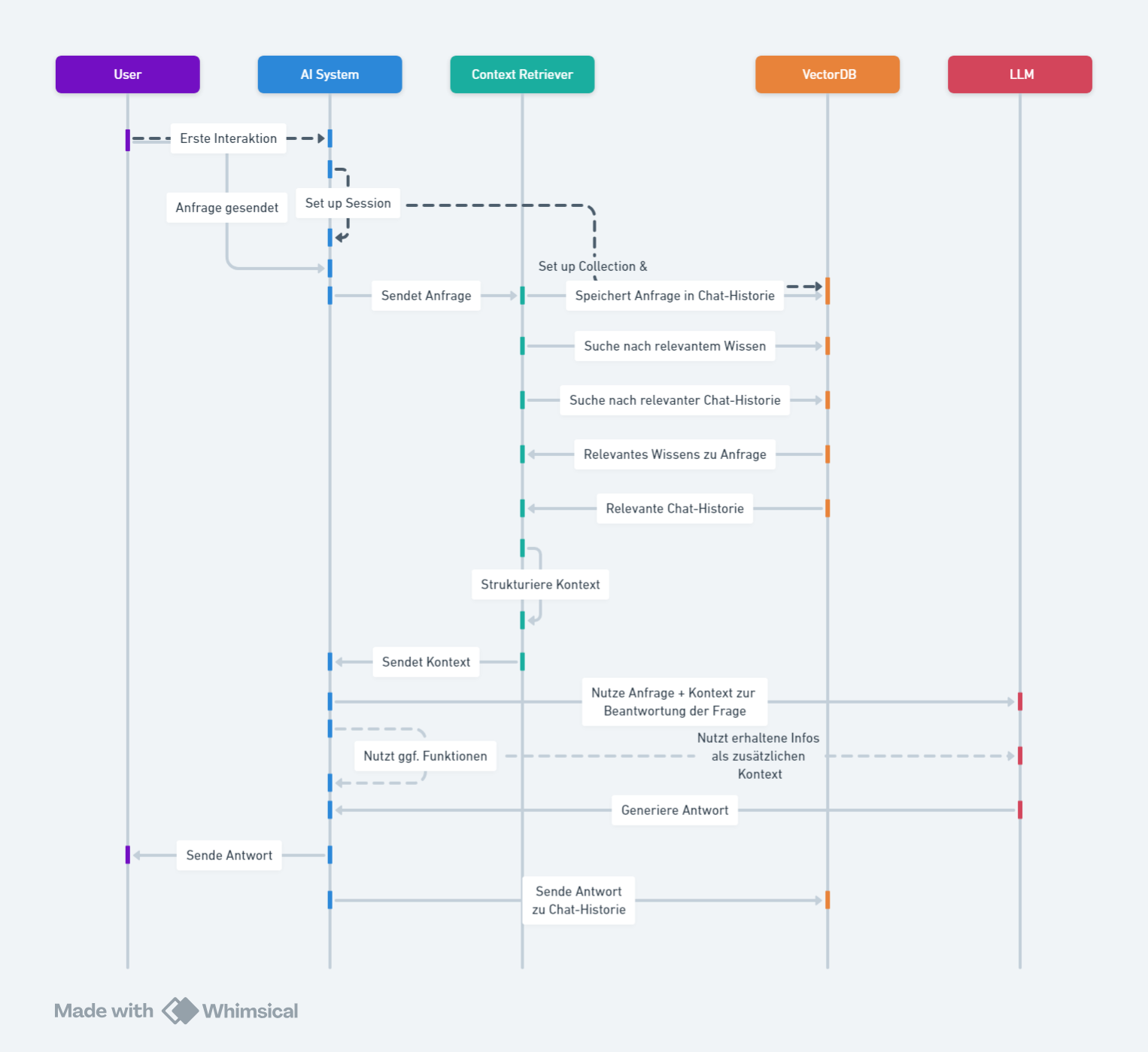
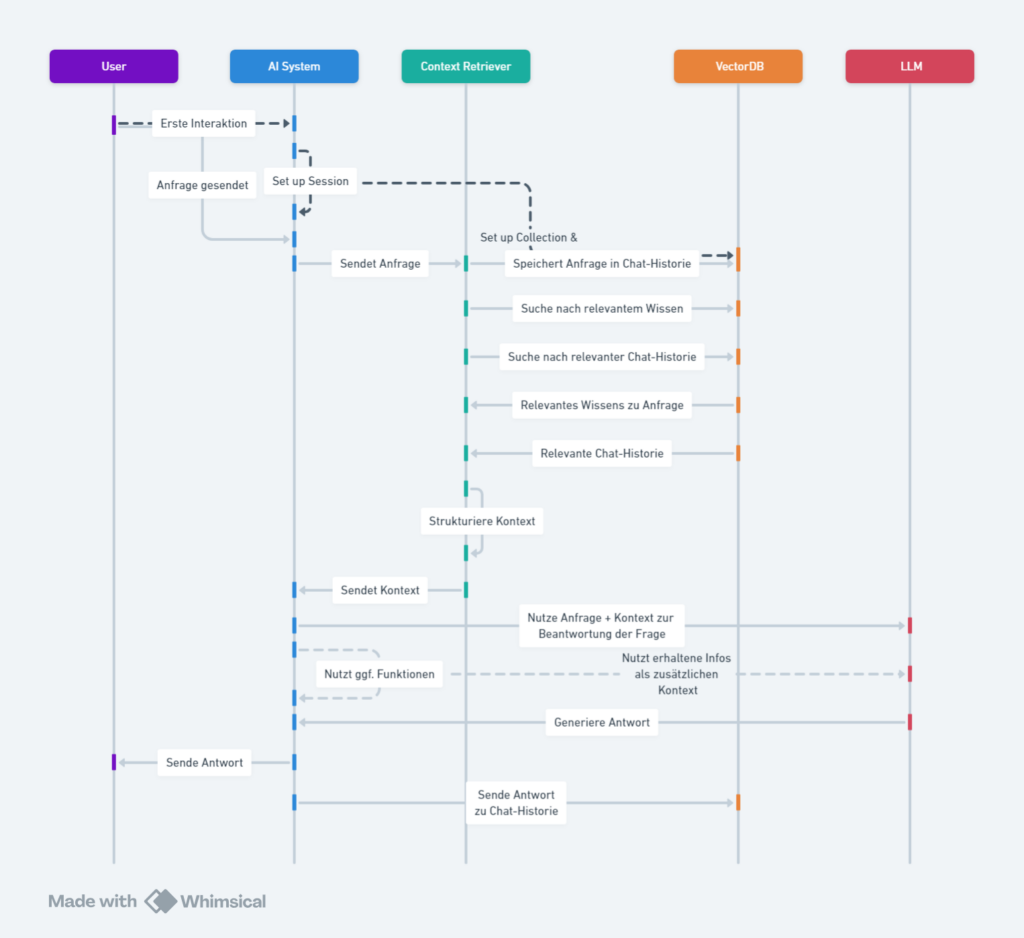
Graph RAG serves as a powerful tool in bridging the gap between textual data and structured knowledge, enabling more accurate and contextual question answering. By leveraging knowledge graphs as a source of context and factual information, Graph RAG enhances the generation of text, ensuring that the outputs are not only linguistically sound but also deeply informed by relevant knowledge.
In the context of knowledge graph interfacing, Graph RAG plays a vital role in addressing key challenges such as hallucination and scalability. By combining the strengths of retrieval and generation, Graph RAG facilitates the creation of more accurate and contextually relevant responses, improving the overall quality of interactions between users and computer systems.
Overall, the adoption of Graph RAG in knowledge graph interfacing represents a significant advancement in the field of natural language processing, opening up new possibilities for chatbots, natural language querying, and information extraction. As this trend continues to evolve, Graph RAG is poised to play a central role in enhancing the accuracy and relevance of information retrieval in computer systems.
Retrieval-Augmented Generation: An Overview
Retrieval-Augmented Generation (RAG) is a cutting-edge machine learning technique that combines the strengths of information retrieval and generative language models to produce highly accurate and contextually relevant responses. The process begins by retrieving relevant information from large-scale knowledge sources such as databases, documents, or the internet. This retrieved information serves as the foundation for subsequent generation tasks, providing a rich contextual understanding for the generative model.
The key advantage of RAG is its ability to produce text that is not only linguistically sound but also deeply informed by the retrieved knowledge, resulting in responses that are both fluent and factually accurate. By leveraging the strengths of both retrieval and generation, RAG enables solutions to craft responses that are tailored to the specific needs of clients and highly relevant to the context at hand.
As the field of natural language processing continues to evolve, RAG has emerged as a powerful tool for enhancing question-answering systems, chatbots, and other applications that require accurate and contextually rich responses. By incorporating external knowledge sources into the generative process, RAG opens up new possibilities for improving the quality and relevance of AI-generated text.
The Power of Knowledge Graphs and Language Models
Knowledge graphs have emerged as a powerful tool in enhancing the capabilities of language models. By providing a structured representation of facts and relationships between entities, knowledge graphs offer a contextual understanding that goes beyond isolated data points. When integrated with language models, knowledge graphs enable a more accurate, context-aware, and semantically rich generation of content.
At the heart of this integration lies the ability of knowledge graphs to infuse semantic richness into language models. By mapping out entities and their interrelations in a way that mirrors human understanding, knowledge graphs enable language models to grasp the meaning behind words and phrases, beyond just syntax. This semantic depth allows language models to generate responses that are not only factually accurate but also logically sound.
Moreover, knowledge graphs provide a contextual framework that allows language models to understand the relationships between concepts. This contextual understanding allows language models to generate responses that are more nuanced and reasoned, offering a deeper insight into the generated content.
To harness the full potential of Knowledge Graph-Augmented Generation (KGAG), it is essential to build a robust knowledge graph. This involves creating a schema that accurately represents the entities and relationships within a domain, utilizing tools for entity recognition and linking, constructing the graph using an appropriate graph database, continually refining and enriching the graph with new data, and integrating it with language models through custom development.
By leveraging the current capabilities of large language models with knowledge graphs, practical steps can be taken to enhance the generation of content. This includes augmenting data feeds with knowledge graphs during training to provide richer context and semantic understanding, as well as using knowledge graphs as a post-processing step for model outputs to ensure accuracy and depth in the generated responses.
In conclusion, the power of knowledge graphs in language models lies in their ability to provide a contextual understanding, semantic richness, and reasoned responses. By integrating knowledge graphs with language models, we can achieve a more insightful and nuanced generation of content that transcends the current capabilities of language models.
Techniques for Graph Retrieval-Augmented Generation
Graph Retrieval-Augmented Generation (Graph RAG) is a powerful technique that enhances text generation by incorporating information from a large dataset or knowledge base. To effectively implement Graph RAG, several techniques can be employed:
- Knowledge Graph Construction: Building a comprehensive knowledge graph that captures the relationships and attributes of entities in the dataset is crucial for effective Graph RAG. Utilizing tools like Neo4j can help in organizing and structuring the data in a graph format.
- Querying and Retrieval: Implementing efficient querying mechanisms to retrieve relevant information from the knowledge graph is essential for accurate text generation. Techniques like graph traversal algorithms can be used to navigate the graph and extract the necessary details.
- Contextual Embeddings: Utilizing contextual embeddings like BERT or GPT models can enhance the understanding of the retrieved information in the generative process. These embeddings capture the context and semantics of the text, improving the quality of the generated output.
- Graph Attention Mechanisms: Incorporating graph attention mechanisms into the generative model can help in focusing on the relevant nodes and relationships in the knowledge graph during text generation. This attention mechanism enhances the coherence and relevance of the generated content.
- Fine-tuning Strategies: Fine-tuning the generative model on graph-specific tasks and datasets can improve the performance of Graph RAG. By adapting the model to the characteristics of textual graphs, the overall accuracy and efficiency of the text generation process can be enhanced.
By employing these techniques, researchers and developers can harness the full potential of Graph RAG for textual graph understanding and question answering applications.
Advantages of Graph Retrieval-Augmented Generation
Advantages of Graph Retrieval-Augmented Generation:
- Scalability: One of the major advantages of using Graph Retrieval-Augmented Generation (Graph RAG) is its scalability. Traditional methods of converting graphs into text sequences result in an excessive number of tokens, surpassing the input capacity of many Large Language Models (LLMs). Graph RAG overcomes this challenge by utilizing retrieval-augmented generation techniques, allowing for the incorporation of information retrieved from a large dataset or knowledge base into the generative process. This ensures that the text generation process remains efficient and scalable, even when dealing with complex and large-scale graphs.
- Improved Contextual Understanding: Graph RAG enhances the generation of text by incorporating contextual information from the graph into the generative process. By retrieving relevant subgraphs from the knowledge graph and enforcing consistency across facts, Graph RAG ensures that the generated text is contextually relevant and knowledge-grounded. This leads to more accurate and informative text generation, especially in tasks that require factual knowledge or detailed information.
- Enhanced Question-Answering Capabilities: Graph RAG can be applied in question-answering frameworks, allowing users to interact with graphs in a conversational manner. By enabling users to „chat with their graph,“ Graph RAG facilitates a more intuitive and interactive way of querying and retrieving information from graphs. This can be particularly useful in scenarios where users need to quickly access specific information from a large graph dataset.
Overall, the advantages of Graph Retrieval-Augmented Generation include improved scalability, enhanced contextual understanding, and enhanced question-answering capabilities, making it a powerful tool for text generation tasks involving complex and large-scale graphs.
Understanding Knowledge Graphs
Knowledge graphs are a powerful tool in the realm of artificial intelligence and natural language processing. They provide a structured representation of knowledge, where entities are connected by relationships, allowing for a more nuanced understanding of information. In a knowledge graph, entities are represented as nodes, and relationships between entities are represented as edges.
One of the key advantages of knowledge graphs is their ability to capture not just individual data points, but also the relationships and dependencies between them. This interconnected structure enables knowledge graphs to handle complex queries that require a deep understanding of the context in which the data exists.
Knowledge graphs follow a semantic triple model, encoding information in subject-predicate-object expressions. For example, a statement like „Mike is 35“ would be represented as a subject (Mike), a predicate (is), and an object (35). This structured representation allows for robust tracing and maintains data fidelity during the retrieval process.
Furthermore, knowledge graphs excel at providing explainability. The explicit definition of relationships between entities allows for a clear traceability of the reasoning path followed by the system to arrive at a particular answer. This transparency enhances trust in the generated responses and provides insights into the decision-making process of the AI system.
In the context of language models, integrating knowledge graphs can significantly enhance the accuracy and context-awareness of content generation. By leveraging the structured representation of knowledge graphs, language models can better understand the semantics of information and produce more insightful and reasoned responses. The combination of knowledge graphs and language models in approaches like Knowledge Graph Augmented Generation (KGAG) opens up new possibilities for creating AI systems that can interact with users in a more human-like manner.
What are Knowledge Graphs?
What are Knowledge Graphs?
Knowledge graphs are dynamic and structured representations of knowledge that capture the relationships and connections between entities in a dataset. In a knowledge graph, entities are represented as nodes, while the relationships between entities are depicted as edges. This setup not only organizes information but also provides a deeper understanding of the context and interrelations among different data points.
For example, in a medical knowledge graph, symptoms like „Cough“ and „Cold“ can be connected to diseases like „Flu“ through relationships such as „symptom of.“ Similarly, treatments like „Rest“ and „Hydration“ can be linked to the disease „Flu“ with relationships like „treated by.“
Knowledge graphs play a crucial role in enhancing the contextual relevance of data retrieval and response generation in AI systems. By leveraging the structured nature of knowledge graphs, AI models can ensure that the information retrieved is not only accurate but also contextually rich, providing a more comprehensive background for generating responses. Additionally, knowledge graphs enable AI systems to handle complex queries efficiently by capturing the intricate relationships and dependencies between entities.
In summary, knowledge graphs serve as powerful tools for organizing, representing, and understanding information in a structured and interconnected manner, making them invaluable for addressing the challenges faced by AI models like Retrieval Augmented Generative models.
Graph Structure and Node Relationships
In the realm of knowledge graphs, the structure of the graph and the relationships between nodes play a crucial role in enhancing the overall understanding and retrieval of information. The interconnected nature of knowledge graphs allows for the representation of complex relationships and dependencies between nodes, providing a deeper context for queries.
One key technique utilized in this domain is the Graph Convolutional Network (GCN), which operates on graphs to model complex relationships. GCNs, including extensions like R-GCN, enable the encoding of text and construction of graphs based on entities mentioned in the knowledge graph. This approach facilitates more accurate answers by considering the relationships between entities and entities within the graph.
Moreover, the use of embeddings in knowledge graphs further enhances search capabilities by transforming text into high-dimensional vectors that capture semantic meaning. Embeddings allow for semantic matching, ensuring that retrieved information closely aligns with the query’s context. By generating node embeddings using tools like Neo4J, knowledge graphs can significantly benefit from improved retrieval capabilities.
When dealing with complex queries, knowledge graphs excel at efficiently handling them due to the deep understanding of context provided by relationships. The integration of various data types offers a unified view that enriches responses, making knowledge graphs a valuable asset in the realm of AI applications, such as in insurance claims processing and querying.
Overall, the structure of knowledge graphs and the relationships between nodes play a vital role in enhancing the search functionalities, analytics, and insights derived from the data. By leveraging advanced techniques like GCNs and embeddings, knowledge graphs can effectively handle complex queries and provide valuable insights for a variety of applications.
Knowledge Graph Queries: Language and Techniques
When it comes to querying knowledge graphs, there are various languages and techniques that can be utilized to extract valuable insights and information. In this section, we will explore some of the key methods and tools used to query knowledge graphs effectively.
- Cypher Query Language: Cypher is a query language specifically designed for querying graph databases. It allows users to interact with the graph data model by specifying patterns to match in the graph. Cypher queries are intuitive and powerful, making it a popular choice for querying knowledge graphs.
- Graph Pattern Queries: Graph pattern queries involve searching for specific patterns within the knowledge graph. These queries can help uncover relationships, entities, and connections between different data points. By formulating precise graph pattern queries, users can extract targeted information from the knowledge graph.
- Text2Cypher: Text2Cypher is a natural language generation graph query method that translates tasks or questions into an answer-oriented graph query. This approach simplifies the querying process by allowing users to input queries in natural language, which are then translated into Cypher queries to retrieve relevant information from the knowledge graph.
- Sub-Knowledge Graph Retrieval: Sub-knowledge graph retrieval involves extracting a subset of the knowledge graph that is relevant to a specific query or task. By retrieving a focused subgraph, users can obtain context and information necessary for answering questions accurately. This technique enhances the efficiency of knowledge graph querying by narrowing down the search space.
- Prompt Engineering: Prompt engineering involves crafting specific prompts or queries to extract desired information from the knowledge graph. By formulating precise prompts, users can guide the querying process and ensure that the retrieved data is relevant to the task at hand. Prompt engineering plays a crucial role in optimizing the performance of knowledge graph queries.
- Graph RAG vs. Text2Cypher: A comparison between Graph RAG and Text2Cypher highlights the differences in their retrieval mechanisms. While Text2Cypher generates graph pattern queries based on the knowledge graph schema and task requirements, Graph RAG focuses on obtaining relevant subgraphs to provide context for answering queries. Understanding the distinctions between these approaches can help users choose the most suitable method for their querying needs.
In conclusion, querying knowledge graphs involves a combination of language, techniques, tools to extract valuable insights from complex data structures. By leveraging the right querying methods, users can unlock the full potential of knowledge graphs and derive meaningful information to support decision-making and problem-solving.
Contextual Understanding in Knowledge Graphs
In the realm of Graph Retrieval Augmented Generation (GRAG), one of the key aspects that sets it apart from traditional methods like Retrieval Augmented Generation (RAG) is the emphasis on contextual understanding. Knowledge graphs play a crucial role in providing a contextual framework that allows language models to grasp the relationships between various concepts, resulting in a more nuanced and insightful generation of content.
When we talk about contextual understanding in knowledge graphs, we are referring to the ability of these structured representations of facts to capture the intricate web of connections between entities and their interrelations. Unlike isolated data points, knowledge graphs offer a holistic view of information, mirroring human understanding by showcasing the contextual nuances that define the relationships between different concepts.
By integrating knowledge graphs with language models, we enable these models to not only generate content based on existing information but also to understand the underlying context in which that information exists. This means that language models powered by knowledge graphs can go beyond simple rephrasing and generate content that is contextually aware, taking into account the broader context in which the information is situated.
The contextual understanding provided by knowledge graphs enhances the semantic richness of language models, allowing them to delve deeper into the meaning behind words and phrases. This deeper semantic understanding enables language models to generate responses that are not just factually accurate but also logically sound, drawing on the contextual relationships encoded in the knowledge graph.
In essence, contextual understanding in knowledge graphs is the key to unlocking the full potential of language models in generating insightful and contextually relevant content. By harnessing the power of knowledge graphs to provide a rich contextual framework, language models can elevate their capabilities to a new level of sophistication, offering a more nuanced and context-aware generation of content.
Retrieval-Augmented Generation in Depth
Retrieval-Augmented Generation (RAG) is a cutting-edge machine learning technique that combines the strengths of information retrieval with generative language models to produce highly accurate and contextually relevant responses. This approach operates by first retrieving relevant information from large-scale knowledge sources, such as databases, documents, or the internet. This retrieved information serves as the contextual foundation for subsequent generation tasks.
The key advantage of RAG is its ability to craft responses that are not only linguistically sound but also deeply informed by the retrieved knowledge, ensuring factual accuracy and contextual relevance. By leveraging the strengths of both retrieval and generation, RAG enhances question-answering systems, enabling them to produce text that is rich in details and tailored to specific needs.
In the context of Graph Retrieval-Augmented Generation (Graph RAG), this technique is further refined to address challenges such as hallucination and lack of scalability in textual graphs. By incorporating knowledge graphs as a source of context or factual information, Graph RAG enhances the accuracy and richness of generated content.
Overall, the evolution from RAG to Graph RAG opens up new possibilities for chatbots, natural language querying, and information extraction. With the transformative potential of Graph RAG, organizations can streamline their data management and analytics work, ultimately improving the quality of interactions with computer systems.
Graph RAG: A Unified Interface for Semantic Matching
In the realm of natural language processing and knowledge graph applications, the need for a unified interface for semantic matching has become increasingly apparent. Traditional approaches to extracting relevant information from knowledge graphs often result in the retrieval of irrelevant or noisy nodes, leading to challenges in effectively representing the interaction between questions and graph entities.
To address these issues, a novel retrieval-augmented knowledge graph (RAKG) architecture has been proposed. This architecture aims to enhance the reasoning capabilities of models by utilizing a corrected knowledge graph for question answering. By extracting an enhanced knowledge graph subgraph, the model is able to obtain accurate reasoning paths, ultimately improving the performance of answer prediction.
One of the key advantages of the RAKG architecture is its ability to address the issue of noisy nodes within knowledge graphs. By continuously updating and refining the knowledge graph through semantic matching, the model can discard irrelevant nodes in a timely manner, preventing negative impacts on answer prediction performance.
Furthermore, the RAKG architecture facilitates a more robust interaction between language models and knowledge graph models. By integrating these two components within a unified interface, the model can better understand complex question-knowledge relations, ultimately enhancing its ability to provide accurate and insightful answers.
Overall, the Graph RAG architecture represents a significant advancement in the field of semantic matching, offering a comprehensive and efficient solution for leveraging knowledge graphs in natural language processing tasks. As researchers continue to explore the potential of this architecture, we can expect further advancements in the development of intelligent question-answering systems and knowledge graph applications.
Textual Graphs in Retrieval-Augmented Generation
In the realm of Retrieval-Augmented Generation (RAG), the use of textual graphs plays a crucial role in enhancing the understanding and question-answering capabilities of large language models (LLMs). Textual graphs, such as scene graphs and explanation graphs, provide a structured representation of information, allowing for a more nuanced and contextually rich understanding of the data at hand.
Unlike traditional knowledge graphs (KG) that primarily focus on semantic relationships between entities, textual graphs capture a wider range of relationships and contextual information, making them versatile tools for enhancing the retrieval process in RAG. By leveraging textual graphs, researchers and practitioners can provide additional context to LLMs, enabling them to better grasp the relationships between entities, reason more effectively, and generate more accurate responses to queries.
In the context of Graph RAG, which utilizes a graph-based retrieval enhancement technique, the incorporation of textual graphs opens up new possibilities for improving question-answering, mitigating hallucination, and fitting data within the context window of LLMs. By treating textual graphs as a rich source of information that complements traditional text-based data, Graph RAG can achieve a more comprehensive understanding of the query intent and deliver more precise search results.
Overall, the integration of textual graphs in Retrieval-Augmented Generation represents a significant advancement in the field of natural language processing, enabling more sophisticated and contextually aware question-answering systems that can effectively leverage both structured and unstructured data for enhanced performance.
Sub-Knowledge Graph Extraction for Precise Search
In the realm of knowledge graph retrieval, the ability to extract sub-knowledge graphs plays a crucial role in enabling precise and accurate search results. Traditional retrieval techniques often struggle to provide detailed and contextually relevant information, leading to challenges such as hallucination and lack of scalability.
With the introduction of Graph RAG and G-Retriever, a new framework for graph question-answering, the focus shifts towards enhancing retrieval through the extraction of sub-knowledge graphs. By leveraging the structured data within a knowledge graph, users can now retrieve specific subsets of information that are directly related to the query intent.
Sub-knowledge graph extraction allows for a more targeted approach to search, enabling users to delve deeper into the relationships between entities and uncover hidden connections that may not be apparent in a broader knowledge graph context. This feature not only improves the accuracy of search results but also enhances the overall user experience by providing more relevant and comprehensive information.
In the context of customer service question answering, for example, the ability to retrieve related sub-graphs from a knowledge graph can greatly streamline the process of resolving customer inquiries. By parsing consumer queries and extracting specific sub-knowledge graphs, businesses can quickly and efficiently generate answers that address the root of the customer’s issue.
Overall, the implementation of sub-knowledge graph extraction within Graph RAG and similar frameworks represents a significant advancement in the field of information retrieval. By enabling precise search capabilities and enhancing the contextual understanding of data, sub-knowledge graph extraction paves the way for more effective and efficient search engines that can better serve the needs of users across various domains.
Node Embeddings and Subgraph Extraction Techniques
Node embeddings and subgraph extraction techniques play a crucial role in enhancing the accuracy and efficiency of knowledge graph extraction and retrieval for question answering. By utilizing node embeddings, we can represent entities in the knowledge graph in a high-dimensional space, capturing the relationships and similarities between them. This allows for more effective retrieval of relevant information and eliminates the retrieval of noisy or irrelevant nodes.
When extracting subgraphs from the knowledge graph, it is essential to focus on relevant entities that are directly related to the question at hand. By filtering out noisy nodes and extracting only the necessary information, the reasoning path for question answering becomes more accurate and concise. This approach ensures that the model can predict answers with higher precision and efficiency.
In previous works, the integration of language models and knowledge graph models as independent components has led to a missing relationship between the question and graph entities. By incorporating node embeddings and utilizing subgraph extraction techniques, we can bridge this gap and provide a more comprehensive understanding of the interactions between questions and graph entities.
Overall, the use of node embeddings and subgraph extraction techniques offers a valuable enhancement to knowledge graph extraction and retrieval systems. By leveraging these techniques, we can improve the performance of question answering models and streamline the process of retrieving relevant information from the knowledge graph.
Fine-tuning Approaches for RAG Models
Fine-tuning approaches play a crucial role in enhancing the performance and accuracy of Retrieval-Augmented Generation (RAG) models. In the context of question answering tasks that involve knowledge graphs, it is essential to optimize the model for better reasoning and understanding of complex relationships between questions and graph entities.
One key aspect of fine-tuning RAG models is the incorporation of a knowledge graph subgraph that is enriched with relevant and accurate information. By extracting an enhanced knowledge graph subgraph, the model can identify a more precise reasoning path for question answering, thus improving the overall accuracy of the predictions. This step is particularly important in filtering out noisy nodes and ensuring that only relevant information is considered during the reasoning process.
In our proposed Retrieval-Augmented Knowledge Graph (RAKG) architecture, we address the issue of limited interaction between language models and knowledge graph models by integrating them into a cohesive framework. This integration allows for a more effective understanding of complex question-knowledge relations, leading to improved performance in question answering tasks.
Furthermore, fine-tuning approaches such as incorporating a bidirectional attention strategy module and leveraging R-Dropout can further enhance the model’s generalization capability and accuracy. These techniques help the model to identify more relevant neighbor nodes, improve the learning of node representations, and ultimately achieve better performance on question answering tasks.
Overall, fine-tuning approaches for RAG models, particularly in the context of knowledge graph-based question answering, are essential for optimizing the model’s performance, improving accuracy, and enhancing its ability to reason effectively. By incorporating these approaches, RAG models can achieve higher levels of accuracy and efficiency in processing complex queries and generating accurate responses.
Applications and Benefits of Graph Retrieval-Augmented Generation
Graph Retrieval-Augmented Generation (RAG) has emerged as a powerful tool for enhancing the capabilities of Large Language Models (LLMs) in various natural language processing tasks. By integrating external knowledge sources through a retrieval information component, RAG enables LLMs to provide more accurate and relevant answers to user queries.
One of the key applications of RAG is in question-answering, where the integration of external knowledge helps reduce hallucinations and improve the overall quality of responses. Additionally, RAG can be utilized for tasks such as information extraction, recommendations, sentiment analysis, and summarization, expanding the range of applications where LLMs can be effectively employed.
Businesses can benefit greatly from implementing RAG in their LLM-enhancing strategies. By reducing hallucinations, providing explainability, and leveraging real-time data sources, RAG enhances the accuracy and specificity of responses generated by LLMs. This not only improves the user experience but also enables businesses to make more informed decisions based on the insights provided by their language models.
The architecture of RAG involves three key processes: understanding queries, retrieving information from external sources, and generating responses based on the combined knowledge. This approach ensures that LLMs have access to the most relevant information available, leading to more accurate and reliable answers to user queries.
Overall, RAG offers a cost-effective and efficient way to augment the capabilities of LLMs by integrating external knowledge sources. Its ability to reduce hallucinations, provide explainability, and leverage real-time data makes it a valuable tool for businesses looking to enhance the performance of their language models and improve the overall quality of their natural language processing tasks.
Enhancing Search Engines with Graph Technology
In the realm of search engines, the integration of graph technology has opened up new avenues for enhancing search capabilities. Traditional search enhancement techniques face challenges such as the need for extensive training data and text understanding issues, which can impact the quality of search results. Graph RAG, a retrieval enhancement technique based on knowledge graphs, offers a promising solution to these challenges by leveraging the power of graph databases and large language models (LLMs).
Graph RAG treats the knowledge graph as a large-scale vocabulary, where entities and relationships correspond to words. By employing a knowledge graph to provide context information and utilizing LLMs for retrieval enhancement, Graph RAG can better understand query intent and deliver more accurate search results. This approach enhances in-context learning, enabling users to build applications that leverage the relationship-rich data stored in a knowledge graph.
The integration of graph technology and deep learning algorithms in Graph RAG represents a significant breakthrough in information retrieval. By harnessing the capabilities of NebulaGraph, developers can effortlessly create knowledge graph applications that benefit from enhanced context learning. The simplicity of building Graph RAG applications with just three lines of code makes it accessible for a wide range of use cases, including complex scenarios like Vector RAG with graph integration.
As graph technology continues to advance, the adoption of Graph RAG in search engines and data processing is poised to grow. The seamless integration of knowledge graphs and graph databases with large language models opens up new possibilities for improving search engine performance and accuracy. Graph RAG stands as a pivotal development in natural language processing, offering a powerful tool for enhancing search engines through the integration of graph technology.
Improving Question-Answering Systems with RAG Models
Question-answering systems play a crucial role in various industries, from customer service to data analysis. With the development of retrieval-augmented generation (RAG) models, there is a significant opportunity to enhance the performance and accuracy of these systems.
RAG models, such as Graph RAG, leverage knowledge graphs to provide context and relationships between entities, leading to more precise and relevant responses. By integrating graph queries into the RAG process, these models can better understand the intent of the query and generate more informed and nuanced answers.
The combination of knowledge graphs and large language models in RAG models like Graph RAG offers a compelling solution for improving question-answering systems. These models not only refine information retrieval by adding context and precision but also enrich language generation, leading to more accurate and relevant responses.
In conclusion, the integration of RAG models in question-answering systems represents a significant advancement in natural language processing. By leveraging the power of knowledge graphs and large language models, these models have the potential to revolutionize the way we interact with and retrieve information from machines.
Chatbots and Customer Service Chatbots Powered by RAG
One of the key use cases for RAG applications is in enhancing chatbots for customer service interactions. By leveraging the power of RAG, chatbots can access a wealth of information stored in databases, documents, and other sources to provide personalized and contextually relevant responses to customer queries.
With RAG, chatbots can tap into product catalogs, company data, customer information, and more to deliver accurate and helpful answers to customer questions. This capability allows chatbots to handle a wide range of tasks, from resolving issues and completing transactions to gathering feedback and improving overall customer satisfaction.
By incorporating RAG into customer service chatbots, organizations can streamline their support processes, increase efficiency, and deliver a more seamless customer experience. These chatbots can handle a variety of queries with ease, drawing on the latest data and information to provide timely and accurate responses.
Overall, RAG-powered chatbots are transforming the way organizations engage with their customers, offering a more personalized and efficient customer service experience that drives customer loyalty and satisfaction.
Real-Time Information Retrieval with Graph RAG
In today’s fast-paced digital landscape, access to real-time information is crucial for businesses to stay competitive and make informed decisions. Retrieval-augmented generation (RAG) applications powered by graph databases offer a powerful solution for organizations looking to retrieve, synthesize, and generate up-to-date information in real time.
Graph RAG applications leverage the interconnected nature of graph databases to access the latest data from multiple sources seamlessly. By storing information in nodes and edges, graph databases enable RAG applications to retrieve relevant data quickly and efficiently. This real-time access to data allows organizations to make timely decisions, respond to customer inquiries promptly, and stay ahead of market trends.
One common use case for real-time information retrieval with Graph RAG is in customer support chatbots. By integrating customer data, product catalogs, and company information into a graph database, RAG chatbots can provide personalized and accurate responses to customer queries in real time. This not only enhances customer satisfaction but also streamlines the support process by resolving issues efficiently.
Additionally, Graph RAG applications are invaluable in business intelligence and analysis. By incorporating the latest market data, trends, and news into a graph database, organizations can leverage RAG to generate insights, reports, and actionable recommendations in real time. This enables businesses to make data-driven decisions quickly and adapt their strategies to changing market conditions.
In the healthcare industry, real-time information retrieval with Graph RAG can revolutionize patient care and treatment decisions. Healthcare professionals can access relevant patient data, medical literature, and clinical guidelines stored in a graph database to make informed decisions on treatment plans. By surfacing potential drug interactions and suggesting alternative therapies based on the latest research, Graph RAG applications empower healthcare providers to deliver personalized and effective care to their patients.
Overall, real-time information retrieval with Graph RAG offers organizations a powerful tool to access and leverage up-to-date data for a variety of use cases. By harnessing the capabilities of graph databases and RAG technology, businesses can enhance their decision-making processes, improve customer interactions, and drive innovation in their respective industries.
The Future of Graph Retrieval-Augmented Generation
As the field of natural language processing continues to evolve, the Graph RAG approach represents a promising future for enhancing the capabilities of large language models (LLMs) in generating more accurate and contextually informed responses. By leveraging knowledge graphs to model the relationships between entities and relationships, Graph RAG opens up new possibilities for handling complex and nuanced queries with greater precision.
Moving forward, the integration of graph technology with retrieval-based and generative approaches is expected to revolutionize various applications, from advanced chatbots to sophisticated data analysis tools. The ability of Graph RAG to provide more accurate search results by jointly modeling entities and relationships during retrieval holds great potential in improving the overall quality of outputs and expanding the capabilities of LLMs.
With ongoing advancements in graph databases and natural language processing techniques, the future of Graph RAG looks promising in enabling more efficient and effective search results that better meet the expectations of users. By combining the strengths of graph technology and large language models, Graph RAG is poised to play a pivotal role in the field of natural language processing and drive innovation in the development of intelligent and contextually aware systems.
Advancements in Prompt Engineering and Model Architecture
The field of artificial intelligence and natural language processing has seen significant advancements in prompt engineering and model architecture, especially in the context of knowledge-grounded dialogue generation and graph question-answering tasks. With the introduction of techniques such as Graph Retrieval-Augmented Generation (Graph RAG) and Retrieval-Augmented Generation (RAG), researchers have been able to enhance the generation of text by incorporating information retrieved from large datasets or knowledge bases.
One of the key challenges addressed by these advancements is the integration of factual knowledge into dialogue generation tasks. Traditional language models often struggle to generate context-relevant responses that incorporate factual information. By leveraging knowledge graphs and subgraph retrieval techniques, models like SUbgraph Retrieval-augmented GEneration (SURGE) are able to retrieve relevant information from structured knowledge bases and ensure consistency across facts in generated responses.
Additionally, advancements in prompt engineering have led to the development of more flexible and scalable graph question-answering frameworks like G-Retriever. These frameworks allow users to interact with graphs directly, enabling them to „chat with their graph“ and obtain answers to complex queries. By combining retrieval-augmented generation techniques with graph-based data representations, researchers have been able to overcome challenges such as hallucination and lack of scalability in graph question-answering tasks.
Overall, the integration of knowledge graphs, subgraph retrieval techniques, and advanced prompt engineering methods has paved the way for more accurate, knowledge-grounded dialogue generation and graph question-answering systems. These advancements hold great promise for improving the capabilities of artificial intelligence models in understanding and generating text based on complex, structured data sources.
The Role of Openness and External Knowledge in RAG
In the implementation of Recursive Autoencoders for Graphs (RAG), the role of openness and external knowledge plays a crucial part in enhancing the effectiveness and quality of the results. Openness refers to the ability to fetch relevant and high-quality data to send to the Language Model (LLM), ensuring that the information provided is accurate and contextually rich. External knowledge, on the other hand, involves integrating structured entity information from external sources, such as graph databases, to provide the LLM with a deeper understanding of the data.
By incorporating external knowledge sources like graph databases into the RAG framework, known as Graph RAG, the system can offer a more comprehensive view of the data by including entity properties and relationships. This integration allows the LLM to gain deeper insights and make more informed decisions based on the contextual information provided.
Moreover, the transparency of the results generated by Graph RAG is essential for building trust and usability in the system. Techniques such as prompt engineering can be utilized to encourage the LLM to explain the source of the information included in its answers, enhancing transparency and reliability.
In conclusion, the integration of openness and external knowledge in RAG, particularly in the form of Graph RAG, can significantly improve the quality and effectiveness of the system by providing contextual richness, deeper insights, and transparency in the generated results. This approach enables a more robust and reliable AI system capable of handling dynamic knowledge and delivering accurate and relevant information to users.
RAG Models and Generative Models for Complex Queries
In the realm of artificial intelligence, Retrieval-Augmented Generation (RAG) models are revolutionizing the way we approach complex queries and generative tasks. These models, which combine the power of large language models (LLMs) with external data sources, offer a new frontier in natural language understanding and information retrieval.
RAG models address the limitations of traditional LLMs by augmenting generated responses with information retrieved from external data stores such as databases, documents, or websites. This integration of retrieval and generation capabilities enables RAG models to provide more precise and contextually rich answers to complex queries, making them invaluable tools for organizations seeking smarter and more informed AI applications.
The key benefit of RAG models lies in their ability to bridge the gap between general language tasks and domain-specific knowledge. By leveraging external data sources, RAG models can access proprietary and industry-specific information, enabling them to provide more accurate and relevant responses to specialized queries.
In industries ranging from healthcare to finance to entertainment, RAG applications are making a significant impact by enhancing the capabilities of chatbots, search engines, and other AI-driven systems. By leveraging the power of RAG models, organizations can deliver more personalized and insightful experiences to their users, ultimately driving greater efficiency and customer satisfaction.
As the field of artificial intelligence continues to evolve, RAG models are poised to play a central role in enabling more sophisticated and contextually aware AI applications. By combining the strengths of generative models with the retrieval capabilities of knowledge graphs, RAG models offer a powerful solution for tackling complex queries and unlocking new possibilities in natural language processing.
From Simple Queries to Nuanced and Complex Questions
As the field of AI continues to advance, the ability to interact with graph data through natural language processing is evolving rapidly. The integration of retrieval-augmented generation (RAG) models with knowledge graphs is enabling a shift from simple queries to nuanced and complex questions.
Traditionally, AI models were limited to answering straightforward questions based on publicly available data. However, with RAG, organizations can now train their AI systems to utilize proprietary data, leading to more personalized and accurate responses. This customization allows for a deeper understanding of domain-specific knowledge, reducing the risk of inaccuracies or hallucinations in generated content.
The challenges of handling complex queries have also been addressed through RAG. By retrieving relevant information from large-scale knowledge sources and leveraging contextual understanding, RAG models can craft responses that are not only linguistically sound but also deeply informed by the retrieved knowledge. This approach enables the AI to tackle intricate questions that require a deep understanding of relationships and contexts, ultimately providing comprehensive and relevant responses.
In conclusion, the integration of RAG models with knowledge graphs is transforming the way we interact with graph data, moving us from simple queries to nuanced and complex questions. By combining the strengths of retrieval and generation, RAG is paving the way for more accurate, contextually relevant, and tailored AI responses in a variety of industries and applications.
Bridging the Gap between Human Language and Graphs
The advancement of technology in the field of artificial intelligence has brought about new possibilities in bridging the gap between human language and graphs. The integration of knowledge graphs with language models has paved the way for more sophisticated and intuitive interactions between machines and humans.
Knowledge graphs, with their dynamic structured representation of knowledge, provide a framework for capturing not just information but also the relationships and context among data points. By connecting entities through relationships, knowledge graphs offer a comprehensive view of information, making it easier for machines to understand and interpret complex data structures.
On the other hand, language models like Retrieval Augmented Generation (RAG) have revolutionized how machines generate and comprehend human language. By combining retrieval-based techniques with generative models, RAG models can fetch relevant information from vast datasets and craft responses that are not only accurate but also contextually rich. This approach has set new standards in creating AI systems that can converse, answer, and interact in ways more aligned with human understanding.
The synergy between knowledge graphs and language models opens up a world of possibilities in various applications. From question answering and common sense reasoning to scene understanding and knowledge graph reasoning, the integration of these technologies enables machines to interact with textual graphs in a more intuitive and user-friendly manner. Imagine being able to chat with your mind map, request specific information from a knowledge graph, or design educational tours through a graph-based interface – all through a simple chat window.
In conclusion, the integration of knowledge graphs with language models like RAG represents a significant step towards bridging the gap between human language and graphs. This fusion of technologies not only enhances the understanding and generation of human language but also enables more intuitive interactions with textual graphs, paving the way for more advanced and user-friendly AI applications.